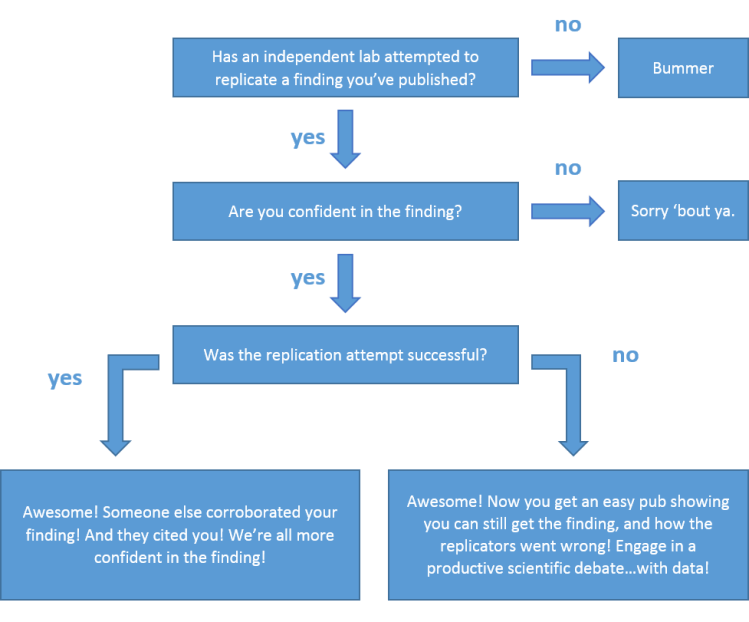
In response to the reproducibility crisis, some in the field have called for a “CERN for Psychology.” I believe the time is right for building just such a tool in psychology science by building on current efforts to increase the use of multi-site collaborations.
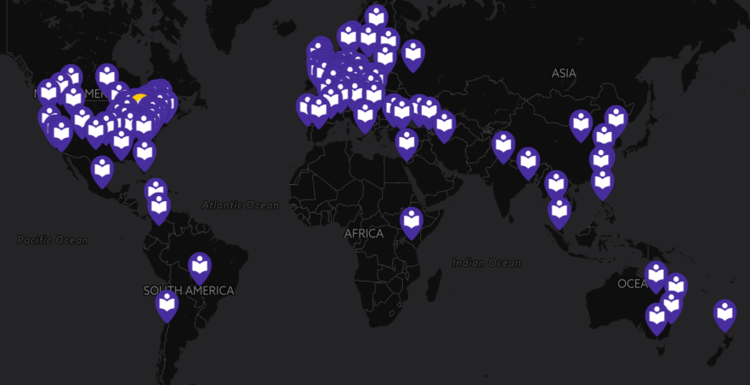
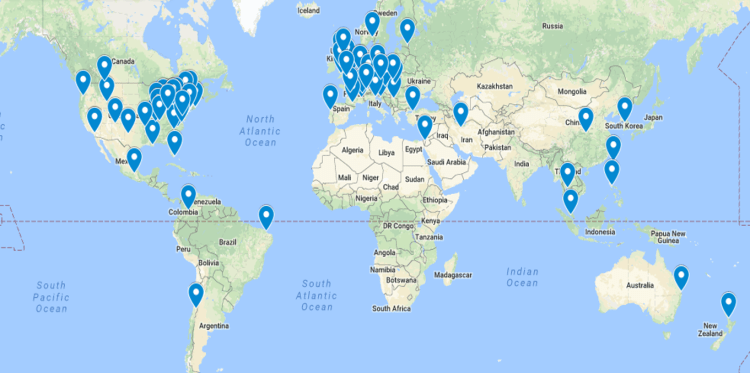
What would a CERN for Psych look like? It certainly would not be a massive, centralized facility housing multi-billion dollar equipment. It would instead be comprised of a distributed network of hundreds, perhaps thousands, of individual data collection laboratories around the world working collaboratively on shared projects. These projects would not just be replications efforts, but also tests of the most exciting and promising hypotheses in the field. With StudySwap, an online platform for research resource exchange, we have taken small steps to begin building this network.
Ideally, a CERN for Psych would also have a democratic and decentralized process for the selection of projects to devote collective resources to. Researchers could propose exciting study proposals, publicly post them, and the community of laboratories comprising the distributed network would decide autonomously and freely which projects to devote their resources to. This could be seen as a new form of peer review. Only those projects that a collection of one’s peers deem worthy of time and energy will be supported with large-scale data collection. The most exciting and methodologically sound ideas, as determined by the community, would be those receiving the greatest amount of resources. Again, StudySwap already provides a basic starting point for this feature and can eventually fulfill this requirement more fully with changes to the site.
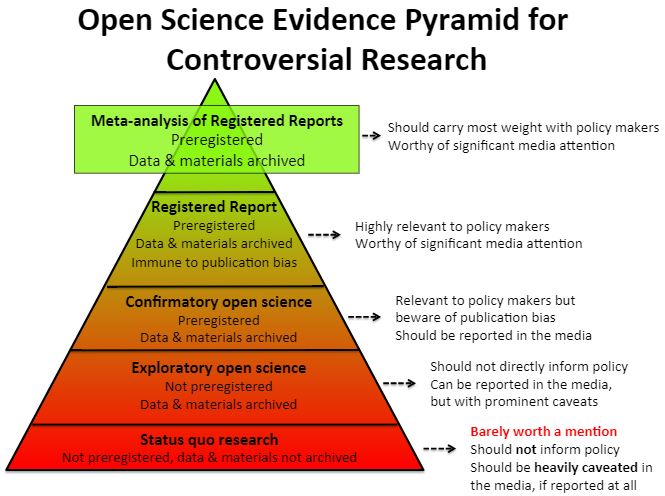
Finally, a CERN for Psych should involve projects that are open and transparent for their full research life cycle. Using the Open Science Framework, projects would be open from idea proposal to methods development to data collection to eventual dissemination. Any interested party could fully review, criticize, praise, build upon, or reanalyze any component of the projects, their data, and their disseminated summaries.
This is not a pipe dream. The basic constituent parts are already in place, but there is much work to be done. What do we need to build a CERN for Psych?
-We need a large distributed laboratory network. If even 10% of psychological scientists devote a small portion of their lab resources to the CERN for Psych, we would be able to harness a massive amount of data collection capacity. This work has already begun, and dozens of labs have signed on for these efforts. Please join the network by filling out this 3-item form.
-We also need researchers who want to use the network to test important hypotheses and who are brave enough to take an innovative approach to their data collection practices. I believe that if we build it, they will come. We are currently recruiting 10 labs to each collect data from 100 participants in 2018 (Total N = 1,000) for just such a proposed study from someone not on the collection team. We will release a call in the near future soliciting study proposals from researchers without access to large samples at their home institutions and who can demonstrate that they would particularly benefit from a geographically dispersed and relatively diverse sample. Email me (cchartie@ashland.edu) if you have ideas you’d already like to propose. This will be a small demonstration of the feasibility of such projects.
-We also know we need a better online platform for StudySwap. The current page, using the OSF for meetings structure was a short term hack that we are already outgrowing after just 6 months. The new site will need much more sophisticated searching, tagging, and categorizing capabilities. We are working with OSF on these improvements.
-We need funding. For now, we can build the beginnings of a CERN for Psych without big money, but eventually, this endeavor will be much more successful with financial resources at our disposal. We are actively seeking funding to support early adopters of this system.
Please join us in building a CERN for Psych. Eventually, this project could involve data collection from millions of participants, conducted by thousands of research assistants, supervised in hundreds of labs, coordinated by a democratically selected and constantly changing set of dozens of leaders in the field.
Dr. Christopher R. Chartier
Associate Professor of Psychology
Ashland University International Collaboration Research Center